Observabilidade Kubernetes na Era da IA: Por Que Estratégias Tradicionais Estão Falhando
Descubra por que workloads de IA estão quebrando estratégias de observabilidade tradicional no Kubernetes e como adaptar seu monitoramento.
—
Introdução
Você já notou que suas ferramentas de observabilidade parecem não funcionar tão bem quanto antes? Não é impressão sua. Workloads de inteligência artificial estão mudando fundamentalmente como aplicações se comportam no Kubernetes.
Neste artigo, vamos explorar por que a observabilidade tradicional está falhando para workloads de IA e como sua equipe pode se preparar para essa nova era.
—
O Que Mudou
Workloads de IA são fundamentalmente diferentes das aplicações tradicionais:
- Picos imprevisíveis: Processamento de modelos causa picos súbitos de CPU/GPU
- Latência variável: Inferência pode levar de milissegundos a minutos
- GPU como recurso crítico: Não apenas CPU e memória
- Logs volumosos: Métricas de treinamento geram massivos volumes de dados
—
Por Que Estratégias Tradicionais Falham
1. Métricas de CPU São Insuficientes
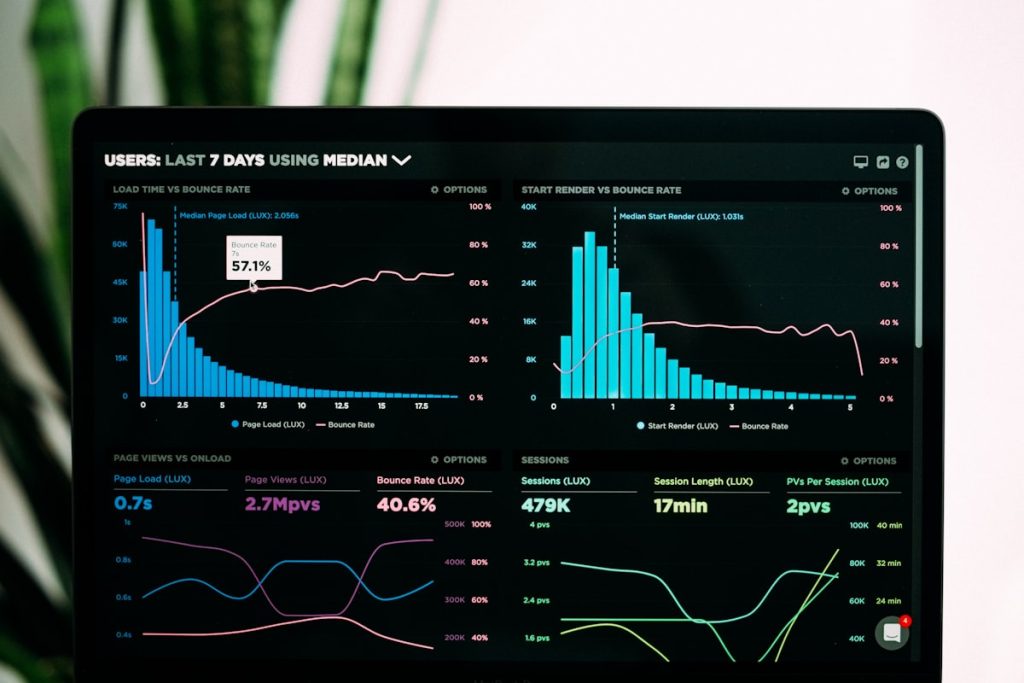
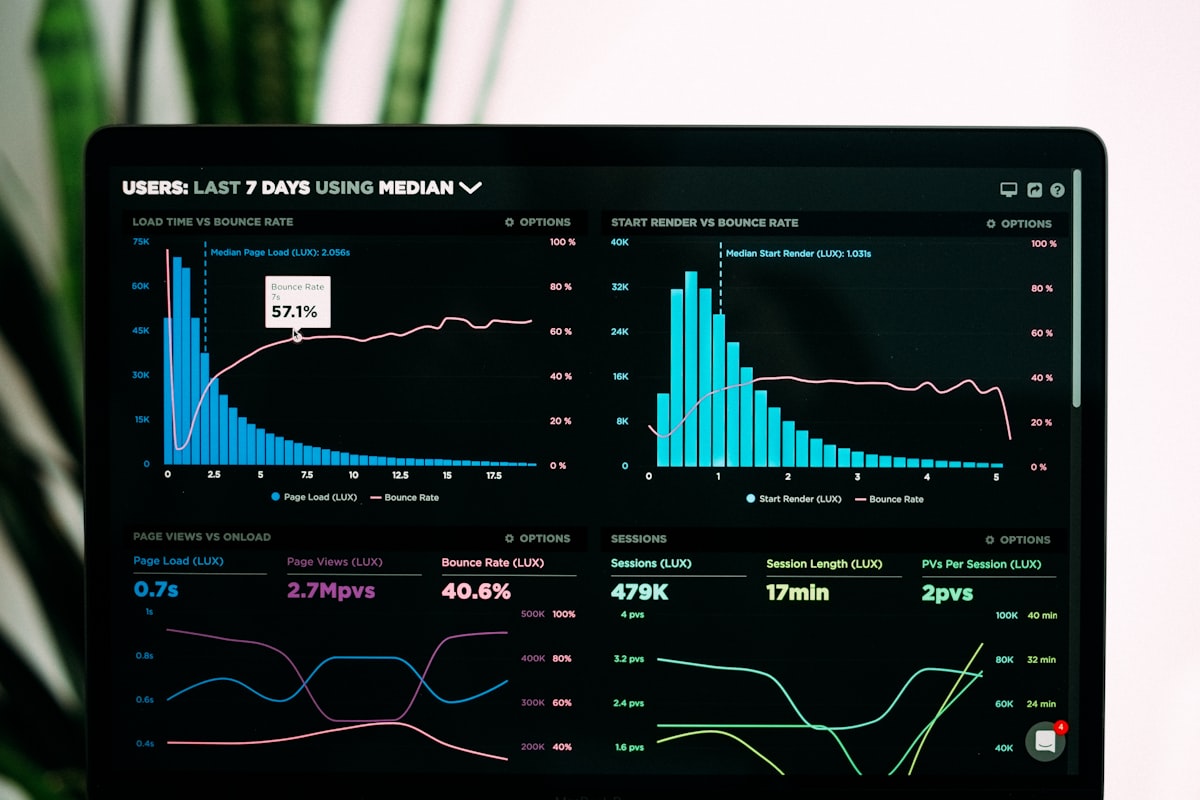
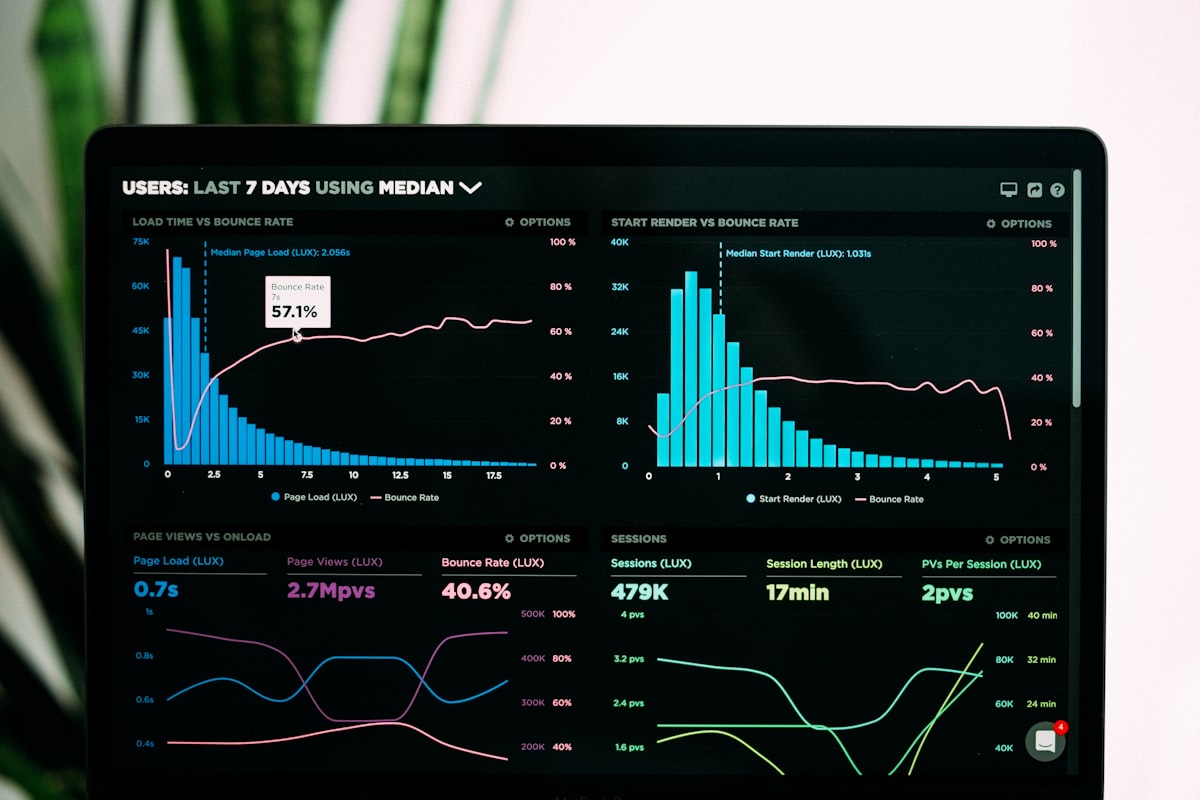
Para workloads de IA, CPU é frequentemente irrelevante. O gargalo está na GPU, mas a maioria das ferramentas não monitora GPU por padrão.
2. Latência Não Segue Distribuições Normais
Latência de inferência é frequentemente bimodal: cache hit (10-50ms) vs cache miss (500-5000ms). Uma média de 250ms não representa nenhum dos casos.
3. Logs São Volumosos Demais
Logs de treinamento com milhares de iterações sobrecarregam ferramentas tradicionais.
4. Traces São Complexos Demais
Pipelines de IA envolvem paralelismo massivo e computação distribuída.
5. Auto-scaling Baseado em CPU Falha
GPU pode estar saturada enquanto CPU está idle.
—
Novas Métricas Para Workloads de IA
Métricas de GPU
- gpu_utilization_percent
- gpu_memory_used_bytes
- gpu_temperature_celsius
Métricas de Modelo
- model_inference_latency_seconds
- model_throughput_requests_per_second
- model_cache_hit_ratio
—
Como Adaptar Sua Observabilidade
Passo 1: Instrumentação de GPU
Configure DCGM Exporter para métricas de GPU NVIDIA.
Passo 2: Métricas Customizadas de Modelo
Implemente exportadores Prometheus específicos para seus modelos.
Passo 3: Alertas Adaptativos
Configure alertas que consideram contexto e bimodalidade.
Passo 4: Dashboards Especializados
Crie painéis para GPU, modelo e pipeline.
Passo 5: Sampling Inteligente
Implemente sampling para logs volumosos.
—
Ferramentas Recomendadas
- NVIDIA DCGM: Monitoramento de GPU
- Prometheus + Grafana: Métricas customizadas
- Jaeger: Tracing distribuído
- MLflow: Rastreamento de experimentos
—
Benefícios Para SOC e NOC
Para SOC
- Visibilidade de ameaças em IA
- Detecção de anomalias de comportamento
- Compliance de GPU
Para NOC
- Diagnóstico preciso (GPU vs modelo vs infra)
- Capacidade preditiva
- SLIs específicos para workloads de IA
—
Casos de Uso
E-commerce com Recomendação
- Descobriu 30% de cache misses desnecessários
- Reduziu P99 de latência de 3s para 200ms
Fintech com Detecção de Fraude
- Configurou alertas de accuracy drift
- Detectou degradação de modelo proativamente
—
Perguntas Frequentes
Preciso de GPUs para observabilidade?
Não. As ferramentas podem rodar em CPUs normais.
Prometheus é suficiente?
Você precisará de exportadores de GPU e métricas customizadas.
—
Como a Linux Managed Pode Ajudar
A Linux Managed oferece serviços especializados:
- Auditoria de observabilidade atual
- Implementação de métricas de GPU
- Dashboards especializados
- Treinamento de equipes SOC e NOC
Contato:
- Site: linuxmanaged.com
- Email: contato@linuxmanaged.com
- WhatsApp: +55 (81) 98932-2830
—
Publicado em 17 de março de 2026 por Igor Ferreira
Tabela Comparativa: Tradicional vs IA
| Característica | Tradicional | IA |
|---|---|---|
| Métricas principais | CPU, memória, tráfego | GPU, VRAM, throughput de modelo |
| Latência | Distribuição normal | Bimodal ou multimodal |
| Alertas | Thresholds fixos | Thresholds dinâmicos |
| Traces | Linear | Com ramificações |
| Logs | Estruturados | Volumosos, semi-estruturados |
| Auto-scaling | Baseado em CPU | Baseado em GPU e fila |
—
Implementação Prática
Configuração do Prometheus para GPU
“yaml
- job_name: 'nvidia-gpu'
static_configs:
- targets: ['gpu-exporter:9400']
metrics_path: /metrics
`
Métricas Customizadas com Python
`python
from prometheus_client import Histogram, Counter, Gauge
inference_latency = Histogram(
'model_inference_latency_seconds',
'Latência de inferência do modelo',
buckets=[0.01, 0.05, 0.1, 0.5, 1.0, 5.0, 10.0]
)
inference_requests = Counter(
'model_inference_requests_total',
'Total de requisições de inferência'
)
model_queue = Gauge(
'model_queue_depth',
'Profundidade da fila de requisições'
)
`
Alerta Adaptativo
`yaml
- alert: ModelInferenceSlow
expr: |
histogram_quantile(0.95,
rate(model_inference_latency_seconds_bucket[5m])
) > 5.0
and on() model_queue_depth > 10
for: 2m
annotations:
summary: "Inferência lenta com fila acumulada"
`
---
Erros Comuns na Implementação
Erro 1: Ignorar Métricas de GPU
Muitas equipes continuam monitorando apenas CPU e memória, perdendo visibilidade do gargalo real.
Solução: Implemente DCGM Exporter desde o início.
Erro 2: Alertas Baseados em Médias
Médias escondem a natureza bimodal da latência de inferência.
Solução: Use histogramas e percentis (P50, P95, P99).
Erro 3: Auto-scaling Baseado em CPU
Escalar baseado em CPU pode piorar a performance se GPU for o gargalo.
Solução: Implemente Custom Metrics Autoscaler baseado em fila e GPU.
Erro 4: Logs Sem Sampling
Coletar 100% dos logs de treinamento é inviável em escala.
Solução: Implemente sampling inteligente (100% erros, 10% info).
Erro 5: Dashboards Genéricos
Dashboards criados para aplicações tradicionais não mostram métricas relevantes.
Solução: Crie dashboards específicos para GPU, modelo e pipeline.
---
Métricas de Sucesso
Como saber se sua observabilidade está funcionando?
| Métrica | Antes | Depois (Meta) |
|---|---|---|
| Tempo para identificar gargalo | 60min | <10min |
| Falsos positivos de alerta | 70% | <20% |
| Cobertura de métricas de GPU | 0% | 100% |
| Precisão de auto-scaling | Baixa | Alta |
| Satisfação da equipe NOC | Baixa | Alta |
---
Tendências Futuras
IA na Observabilidade
Modelos de IA estão sendo usados para automaticamente detectar anomalias em métricas de IA — uma camada extra de inteligência.
Observabilidade Serverless para IA
Em ambientes serverless com workloads de IA, a observabilidade precisa ser ainda mais eficiente.
Edge Computing
Em edge, com recursos limitados, observabilidade verde + específica para IA é obrigatória.
---
Próximos Passos
Se você reconhece os problemas descritos, aqui estão ações imediatas:
1. Audite suas métricas atuais: Você monitora GPU?
2. Identifique workloads de IA: Quais aplicações usam modelos de ML?
3. Configure DCGM Exporter: Comece pela instrumentação de GPU
4. Crie dashboards específicos: Painel de GPU + Painel de Modelo
5. Implemente alertas adaptativos: Considere bimodalidade
---
Workloads de IA exigem observabilidade de IA. Adapte ou fique para trás.
Checklist de Implementação
Use este checklist para implementar observabilidade de IA no Kubernetes:
Planejamento
- Identificar todos os workloads de IA no cluster
- Mapear quais nodes têm GPU
- Definir SLIs específicos para cada workload
- Identificar ferramentas de observabilidade atuais
Instrumentação
- Instalar DCGM Exporter em nodes com GPU
- Configurar ServiceMonitors para GPU
- Implementar métricas customizadas em cada modelo
- Configurar tracing distribuído
Visualização
- Criar dashboard de GPU (utilização, memória, temperatura)
- Criar dashboard de modelo (latência, throughput, cache)
- Criar dashboard de pipeline (estágios, erros, volumes)
Alertas
- Configurar alertas de saturação de GPU
- Configurar alertas de latência de inferência
- Configurar alertas de accuracy drift
- Implementar alertas baseados em anomalias
Otimização
- Implementar sampling de logs
- Configurar retenção diferenciada
- Otimizar queries do Prometheus
- Testar auto-scaling baseado em métricas customizadas
---
Cenários de Diagnóstico
Cenário 1: Latência Alta em Inferência
Sintomas: P99 de latência acima de 5 segundos
Diagnóstico com observabilidade tradicional:
- CPU parece normal
- Memória parece normal
- Não há erros nos logs
Diagnóstico com observabilidade de IA:
- GPU utilization em 98%
- VRAM fragmentada
- Fila de requisições acumulando
- Cache hit ratio baixo
Ação: Escalar réplicas ou otimizar modelo
Cenário 2: Throughput Baixo
Sintomas: Modelo processando menos requisições que o esperado
Diagnóstico com observabilidade tradicional:
- Tudo parece normal
- Nenhum alerta disparou
Diagnóstico com observabilidade de IA:
- Batch size subótimo
- GPU subutilizada (20%)
- Pipeline bottleneck no estágio de preprocessing
Ação: Otimizar batch size e paralelizar preprocessing
Cenário 3: Degradação Gradual
Sintomas: Performance piorando ao longo de dias
Diagnóstico com observabilidade tradicional:
- Métricas estáveis
- Nenhuma mudança visível
Diagnóstico com observabilidade de IA:
- Accuracy drift detectado
- Distribuição de inputs mudou
- Modelo não generaliza mais para novos padrões
Ação: Retreinar modelo com dados recentes
---
Integração com Zabbix
Se você já usa Zabbix para monitoramento, pode integrar métricas de GPU:
Configuração do Zabbix Agent
`
/etc/zabbix/zabbix_agentd.conf.d/gpu.conf
UserParameter=gpu.utilization,nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader,nounits
UserParameter=gpu.memory.used,nvidia-smi --query-gpu=memory.used --format=csv,noheader,nounits
UserParameter=gpu.memory.free,nvidia-smi --query-gpu=memory.free --format=csv,noheader,nounits
UserParameter=gpu.temperature,nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader,nounits
`
Trigger para GPU Saturada
`
{host:gpu.utilization.avg(5m)} > 90
—
Conclusão
Workloads de IA não são apenas mais uma aplicação no Kubernetes. Eles têm características únicas que exigem abordagens de observabilidade igualmente únicas.
Se sua organização está adotando IA, é hora de repensar sua estratégia de observabilidade. As ferramentas existem — Prometheus, Grafana, DCGM, Jaeger. O desafio é adaptar processos e mentalidades.
A Linux Managed está aqui para ajudar nessa transição. Entre em contato e vamos construir juntos uma observabilidade preparada para a era da IA.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}